
Un retour d'expérience sur le fine tuning de modèles pour améliorer les performances sur un cas d'usage d'extraction de données structurées.
Les modèles fine tuné offrent de meilleures performances que GPT-4o !
Ici le processus de fine tuning a permis au modèle d'augmenter les poids lui permettant de "comprendre" ou étaient les données à extraire.
C'est intéressant mais compliqué à mettre en place entre la constitution du jeu de données et l'évaluation des modèles fine tuné.
Les résultats sont quand même très encourageant, je pense qu'il va falloir de plus en plus considérer le fine tuning pour certains cas d'usages.


Un article de recherche assez impressionnant d’Anthropic, ils ont cartographié l’activation des “neurones” du LLM.
Cela me fait beaucoup penser à l’IRM qui permet de repérer quels sont les zones du cerveau qui s’activent pour une tâche ou à l’évocation d’un concept.
De la même manière, ils ont observé l’activation des “neurones” du LLM lors de la génération afin de repérer quelles zones encodaient les concepts.
C’est une grande avancée dans le domaine de l'explicabilité qui est cruciale pour comprendre le fonctionnement interne des réseaux de neurones informatiques.
OpenAI est arrivé à un tel niveau de qualité dans les réponses faites par ses modèles qu’il est maintenant difficile pour les évaluateurs humains de choisir une meilleur réponse dans leurs processus de Reinforcement Learning (RLHF).
Ils ont donc fine-tuné un modèle (aussi par RLHF) pour aider les évaluateurs à discerner des erreurs ou améliorations.
Le modèle se trompe souvent mais cela améliore quand même de 60% la qualité de l’évaluation.
C’est un très bon exemple de “copilot” IA ou la collaboration entre IA et humain donne de meilleurs résultats la ou l’utilisation de l’IA seule n’aurait pas été possible car trop d’erreurs.
LiveBench est un agrégateur des différents benchmark à destination des LLMs.
Il propose un score qui correspond à la moyenne sur les différents benchmark qui existent.
Afin d’éviter la “contamination” (=triche), c’est à dire que les modèles soient entrainer avec les réponses des benchmark, ils utilisent de nouvelles questions chaque mois.
C’est aujourd’hui Claude 3.5 Sonnet qui tiens la première place avec 61% vs 55% pour GPT-4o.
Le premier modèle Open Source est Mistral Large à la 12e place du classement avec 39%.

Inflection 2.5 est un modèle aux performances comparables à GPT-4.
Un papier scientifique qui explique une méthode pour faire tourner un LLM sans la multiplication des matrices.
En gros ça signifie qu'on aurait pas besoin de l'acceleration GPU pour faire tourner des LLMs mais qu'on pourrait faire ça sur des CPU standard que tout le monde a déjà.
La dernière version de Claude serait le premier modèle à battre un modèle d'OpenAI.
Sur un benchmark de raisonnement par exemple, Claude 3.5 Sonnet fait 59% vs 53% pour GPT-4o.
Le million de token est à 3$ vs 5$ pour GPT-4o et ma fenêtre de contexte est de 200K tokens vs 128 pour GPT-4o.
Le modèle possède également des capacités d'analyse image.
Bref, un sérieux concurrent pour OpenAI !

Une technique intéressante de prompt injection qui passe tous les niveaux du CTF de Lakera (une entreprise spécialisée dans la sécurité des LLMs)
Ils donnent des instructions en pseudo code qui permettent de faire leak le code secret

Perplexity n'utilisent pas le User Agent qu'ils déclarent utiliser.
Cela empêche de bloquer le bot qui scrape les pages web pour Perplexity (et ils ne respectent pas non plus le robot.txt bien évidemment)
La lib Firebase Genkit de Google pour LLM est très bien pensée.
Contrairement à Langchain, le design est simple et le nombre de features limité à des abstraction de bas niveau.
- Abstraction autour des modèles (LLM et aussi image)
- Génération de données structurées avec schéma de validation Zod en entrée et en sortie (on fait la même chose chez Didask)
- Utilisation d'outils par les LLMs (la aussi définis avec Zod!)
Je ne suis pas super fan de leur manière de gérer les templates de prompt par contre, je préfère utiliser du pur Javascript.
Le gros bémol c'est que l'on a pas accès aux modèles d'OpenAI.

Une nouvelle technique qui comme le RAG, est utilisée pour permettre au LLM de répondre à des questions sur des données non présentes dans le corpus d'entrainement initial.
Pour ça, ils se basent sur un fine-tuning de millions de LoRa avec les documents qui seront sélectionnés au moment de l'inférence pour répondre à la question.
Ils annoncent des résultats impressionnants avec 95% de précision sur un cas d'usage Text-to-SQL vs 50% avec un RAG.
Cette méthode permet de remplacer un RAG avec une nouvelle technique d'entrainement mais aussi de réduire énormément les hallucinations.
Ils expliquent les détails de leur méthode dans ce papier de recherche: Banishing LLM Hallucinations Requires Rethinking Generalization
Si ça se concrétise c'est game changer pour l'écosystème LLM qui pourrait délaisser le RAG pour le Memory Tuning dans certains cas d'usage.

Un outil de LLMOps dans la même veine que Langfuse.
Ça permet l'observabilité des applications LLM avec études des étapes de générations et même possibilité de rejouer directement les prompts.
Ils proposent aussi une partie évaluation et une partie création collaborative de prompts.
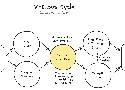
Un très bon article sur la manière d'évaluer des système de GenAI (RAG mais pas que)
- Avoir des interfaces bien foutues pour l'évaluation des données (question + réponse)
- Pas forcément besoin d'outils sophistiqués (même Excel peut faire l'affaire)
- Chaque système nécessite une évaluation personnalisée
- Écrire beaucoup de tests
- Utiliser les LLM pour générer des données de test
- Réutiliser son infrastructure d'évaluation pour le debug et le fine-tuning

Un REX sur l'utilisation de LLMs en production.
Prompt Engineering:
- mettre l'accent sur les techniques de prompting (chain of thought etc)
- travailler sur la structure des données en entrée et en sortie
RAG:
- utiliser de la recherche hybride (vecteur + keyword)
- préférer le RAG au fine tuning pour la recherche de connaissance
- les long contextes des modèles ne rendront pas les RAG obsolètes
LLM Engineering:
- utiliser des workflow LLM qui mélangent prompt engineering et software engineering pour de meilleurs résultats
- faire générer des plans aux Agents afin d'améliorer la reproductibilité des résultats
- ne pas oublier de faire varier les méta-paramètres (temperature, top_p, etc)
- mettre en place des stratégie de cache
Test et évaluation:
- utiliser des tests unitaires avec des exemples réels
- évaluer les résultats avec d'autres LLM
- les évaluations apparaissent entre 5 et 10% du temps même sur des tâches simples
Un article très intéressant sur le caractère probabiliste des LLMs.
En gros, les GPU ont des architectures internes différente, notamment sur la manière de programmer les tâches en parallèle et du à la non associativité de certaines opérations cela cause des infimes différences de calcul qui finissent par affecter significativement le résultat final.
Cela me fait penser à la théorie du chaos ou des différences infimes dans l'état initial amène à des évolutions complètement différentes d'un système.
Un framework Python pour intégrer des LLMs dans son code.
Je trouve la DX bien pensée par rapport à Langchain (pas difficile de faire mieux niveau DX)
On y retrouve simplement les fonctionnalités essentielles pour faire du LLM Engineering:
- choix du modèle, des paramètres
- intégration facile de l'historique de messages
- utilisation de fonctions par le modèle (Function Calling )
- chaines de prompt et sous prompt (vraiment bien foutu je trouve!)
- extraction de données structurées
Il ne manque que la validation et la possibilité de spécifier un format de sortie structuré pour chaque prompt. C'est du super boulot.
(Dommage que ce soit en Python)
Mistral ouvre le fine-tuning de ses modèles.
Techniquement, c'est un fine tuning LoRa ou très peu de paramètres sont affectés. Ça réduit drastiquement les coûts tout en offrant de bonnes performances de génération (selon eux)
Bon alors techniquement c'était déjà possible vu que les modèles sont open source mais concrètement ils simplifient la tâches aux développeurs en proposant 3 services:
- mistral-finetune: open source et gratuit, c'est un repo qui contient le code nécessaire pour fine tuner un modèle Mistral
- Serverless fine-tuning: une API sur leur cloud pour fine-tuner les modèles sans se prendre la tête ($)
- Custom training service: une offre de service ou le fine tuning est pris en charge de A à Z par les équipes de Mistral ($$$)
OpenAI partage des technique pour réduire la latence des LLMs.
C'est toujours bon à prendre car le paradigme de latence des LLMs est assez inédit dans le mode du Software Engineering ou on optimise à la dizaine de micro-seconde.
-
Taille du modèle: plus petit = plus rapide mais surtout moins performance. Si vous n'êtes pas capable de mesurer la performance alors il vaut peut-être mieux ne pas risquer un autre modèle que ceux de la gamme GPT4.
-
Générer moins de tokens: les tokens de sortie sont long à générer et en plus coûtent 2x plus cher. Je partage une de mes technique pour Modifier efficacement un texte avec un Agent LLM par exemple
-
Utiliser moins de tokens en entrée: rien à redire ici
-
Faire moins de requêtes: regrouper les requêtes dans le même prompt réduit la latence mais fait baisser les performances (J'en parle dans Spécialisez vos Agents LLM pour de meilleures performances
-
Paralléliser les requêtes: basic software engineering
-
Montrer la progression à l'utilisateur: basic user experience
-
Ne pas utiliser des LLMs partout: cela ne sert à rien de taper sur une vis avec un marteau

Une utilisation très intéressante de la recherche sémantique: un cache sémantique
Si l'on souhaite utiliser un cache dans une application qui traite du langage naturel (à travers des prompt par exemple), il est très difficile de faire cela avec les techniques traditionnelles comme le hashing.
Plutôt qu'un hash, on peut stocker un vecteur sémantique avec le résultat mis en cache. Ainsi, si une demande ultérieur approche le sens de la première demande, on peut renvoyer directement le résultat.
Par exemple, ces deux questions ne sont écrites pareil mais ont le même sens:
- "En quelle année est sortie Half-Life 2?"
- "Quelle est l'année de sortie de Half-Life2"
Il suffit de stocker le vecteur correspondant à la première question avec la réponse (2004 bien sur!) puis lorsque l'on reçoit la deuxième question on calcule le vecteur et comme il est très proche du premier alors on renvoi la même réponse.
A priori GPT-4o est de loin le meilleur modèle pour le problème de "needle in a haystack" qui consiste à évaluer la performance d'un modèle pour retrouver le texte pertinent dans un prompt très long.
Alors que GPT-4 Turbo, Claude ou Mistral performent à ~50% en moyenne, GPT-4o atteint presque la perfection avec plus de 80% de succès !
Cela veut dire que même avec des très longs prompt, le modèle reste performant. Pratique pour traiter un grand nombre d'informations à la fois.